

Once game-changing, traditional Optical Character Recognition (OCR) and Robotic Process Automation (RPA) are increasingly proving to be legacy tools in modern enterprises. Despite their early promise, many deployments underperform or outright fail. Analysts have noted that a significant percentage of RPA initiatives never meet expectations, Ernst & Young found up to 50% of RPA projects fail to deliver ROI. On the document digitization front, OCR systems frequently falter on anything beyond the simplest, cleanly-formatted texts. As businesses generate and handle more complex, unstructured data than ever, the cracks in these legacy approaches are beginning to show.
Today’s IT professionals and developers demand automation that is accurate, adaptive, and integrated end-to-end into workflows. OCR and RPA, with their brittle rules and narrow scope, struggle to meet these expectations. In this article, we’ll examine evidence of how OCR and RPA fail in practice, from high error rates to maintenance nightmares, and why they are not future-proof. We’ll then explore how Intelligent Document Processing (IDP) and agentic AI systems are emerging as transformative alternatives, delivering adaptability, precision, and seamless workflow integration. Finally, we’ll dive into Lightico’s patent-pending LLM model creation and selection framework, showing how it overcomes the limitations of OCR/RPA both technically and strategically.
The Cracks in OCR and RPA: Frequent Failures in Practice
Traditional OCR and RPA were built for a simpler era of automation. In practice, they often buckle under real-world complexity. Key failure points include:
Brittle, Hard-Coded Rules
RPA bots excel at repetitive tasks only as long as nothing changes. They rely on pre-defined UI selectors, scripts, and templates, making them extremely fragile when interfaces or inputs deviate.
Even a minor change (like an extra column in a spreadsheet or a UI update) can break a bot completely. Gartner analysts describe this brittleness as a source of technical debt: organizations must constantly track every screen and field a bot touches, because a small third-party update can cascade into broken automations.
In short, RPA provides “dumb bots” that don’t cope with variability, one reason 30, 50% of RPA projects end in failure.
High Error Rates from OCR
Traditional OCR engines are essentially pattern-matching tools, great for converting clean printed text into machine-readable form, but clueless about context. They frequently misread or misclassify text, especially when faced with real-world conditions like poor image quality, complex layouts, or handwriting.
These errors translate into false positives (e.g. detecting text that isn’t actually there, or mis-identifying a figure) and incorrect data entering your systems. Since OCR has “limited functionality, focusing solely on text recognition while neglecting context”, it often requires extensive post-processing rules to extract meaning, rules that are themselves brittle.
Inability to Handle Unstructured Data
Perhaps the biggest limitation is that legacy OCR/RPA expect structured, predictable inputs, forms that match templates, screens that stay the same. But enterprise data today is largely unstructured and varied. Documents arrive in all forms: scanned contracts, images with tables, emails full of paragraphs, even handwritten notes. Systems built solely on fixed patterns and templates “can’t keep up” with this diversity.
Their fragility leads to poor performance as soon as input deviates from expected norms. An OCR solution might extract a known invoice format well, but introduce a new vendor layout or a slight format tweak and it fails, often requiring full human intervention to fix. RPA scripts similarly struggle with unstructured inputs, they can’t easily parse free-form text or make sense of documents that weren’t anticipated in their design.
Complex Implementation & Maintenance
Both OCR and RPA come with considerable overhead to implement and maintain. Traditional OCR pipelines require setting up templates or zones for each document type, plus integrating OCR outputs with downstream systems via custom code or RPA bots. RPA, while touted as “low-code”, often ends up creating a spaghetti of bot scripts that are difficult to manage at scale.
As one analysis notes, when you have dozens or hundreds of bots in production, it becomes “hard to find them and understand what programs or data they depend on”, making updates a nightmare. Many organizations have found their RPA efforts stalling after initial pilots, bots are over-used, poorly governed, and fail to scale beyond a few rudimentary processes. The result is disillusionment: promised cost savings or efficiency gains never fully materialize as maintenance and exception handling erode the benefits.
In summary, OCR and RPA tend to automate the easy parts and break on the hard parts. They work best in controlled, simple scenarios.
But modern enterprise operations are anything but simple, they involve high volumes of messy data and constant change. The legacy tools’ lack of flexibility and intelligence leads to numerous points of failure: brittle bots, misread data, constant re-coding, and a heavy reliance on humans to fill in the gaps when the automation fails.
Not Future-Proof: Why OCR and RPA Can’t Meet Modern Demands
Beyond the day-to-day failures, OCR and RPA are fundamentally mismatched to the future of enterprise IT. Modern businesses require agility and learning, attributes these legacy systems were never designed to provide. Consider the trends shaping today’s environment:
Explosion of Unstructured Data
Industry research indicates that 80, 90% of new enterprise data is unstructured, and it’s growing 3X faster than structured data. This includes emails, PDFs, images, chat logs, social media, and more, rich textual and visual information that doesn’t fit neatly into rows and columns.
Legacy OCR/RPA handle structured inputs reasonably well but falter as soon as input data diverges. They were not built to intelligently parse the nuance of a legal contract or the free-form text of a customer email. As unstructured data becomes the norm, systems that can’t natively deal with it are simply not future-proof.
Enterprises stuck on old OCR/RPA pipelines will spend an increasing amount of time writing new rules for each new format, a losing battle given the volume and variety of data.
No Learning or Adaptation
Traditional RPA and OCR are static. They do not improve on their own, an RPA bot will make the same mistake every time until a human updates its script; an OCR engine will misread the same messy handwriting unless explicitly retrained.
This is the opposite of what modern AI-enabled systems offer. Today’s expectation (thanks to machine learning and AI) is that systems continuously learn and adapt from new examples. Gartner analysts point out a critical shift: moving from brittle, case-by-case rules to solutions that leverage ModelOps (machine learning models in production) with continuous learning.
In a modern AI-powered workflow, when a new document type appears, the system can learn from it (updating a model or adjusting automatically) rather than requiring a developer to hard-code a new rule.
OCR and RPA lack this capability, they remain stuck in a “programmed” paradigm. This inability to evolve quickly means they struggle to meet developers’ and users’ expectations for rapid improvement and adaptation.
Developer and User Expectations
Speaking of expectations, consider the experience of implementing automation today. Developers and IT teams expect open APIs, cloud scalability, and modular integration into their stacks. Legacy OCR engines often come as heavyweight on-premise software or closed systems that are hard to integrate with modern cloud apps. RPA tools, while improving, have historically been GUI-driven and targeted at non-developers (business users automating in a silo).
This has led to cases where business units spin up bots that later become unmanageable “shadow IT” for developers. Modern enterprises are moving toward composable services and AI microservices, small, focused AI models that can be called on-demand and orchestrated via code. In this landscape, monolithic OCR or fragile UI scripts feel archaic.
Enterprise decision-makers also demand clear ROI and scalability. Yet, as noted, many RPA deployments fail to scale beyond pilots and end up with uncertain ROI. The “hype cycle” of RPA is over, now people ask hard questions about maintenance overhead and long-term viability.
Unfortunately, RPA often “codifies inefficiencies” (automating a bad manual process rather than improving it), and can create as much work as it saves in the long run. These shortcomings make it hard for RPA/OCR to meet the strategic demands of digital transformation initiatives.
Rigid Architecture vs. Agile Workflows
In a environment, processes don’t stay static. Mergers happen, systems get upgraded, regulations change forms, automation must keep up. RPA and OCR are inherently fragile to change. An organization that builds dozens of bots to navigate one system may have to redo them all when a new system is put in place. Gartner observes that most RPA products support change management “very poorly, ” leaving organizations to manually track what each bot touches.
This is anathema to agile DevOps practices. In contrast, the future is moving toward declarative AI-driven workflows, define the goal or outcome, and let adaptive systems figure out the steps. Legacy tools can’t do that; they only do exactly what they were told, nothing more.
Strategically, this means they age poorly. A workflow automated with static scripts might work today, but it won’t automatically adjust to the needs of tomorrow. Enterprises end up constantly playing catch-up, updating bots and OCR templates, rather than focusing on higher-level innovation.
In short, OCR and RPA struggle to meet modern enterprise expectations of flexibility, intelligence, and resilience. They were breakthrough technologies in their time, but they are not inherently designed for an AI-driven future. As data and processes grow more complex, the gap between what legacy automation can handle and what businesses actually need is widening.
This gap has paved the way for a new generation of solutions that are built with AI at the core, aiming to be adaptive, precise, and end-to-end by design. Enter Intelligent Document Processing and agentic AI.
From Automation to Intelligence: How IDP and Agentic AI Are Changing the Game
If OCR and RPA are the “first draft” of automation, Intelligent Document Processing (IDP) and agentic AI represent the next chapter, one that learns from the failings of its predecessors. These AI-powered approaches are transforming enterprise automation by addressing the very pain points we outlined: adaptability to any data, far greater accuracy, and holistic integration into workflows (rather than narrow tasks). Let’s break down what these entail and why they’re fundamentally more capable:
Intelligent Document Processing (IDP) is often described as the evolution of OCR. Rather than just extracting text, IDP platforms combine OCR with advanced machine learning (ML) and natural language processing (NLP) to actually understand documents.
As one source puts it, IDP is “the ultimate document processing mastermind”, it can interpret context, categorize documents, extract key data points, and even validate information for accuracy.
In practical terms, an IDP system might ingest a stack of diverse documents (applications, contracts, invoices), automatically classify each document type, and pull out the relevant fields (names, dates, totals, etc.) with minimal prior rules.
The ML models are trained on large datasets of documents, so they learn patterns that generalize, when a new format appears, the system can often handle it by inference, not by explicit instruction. This is a game-changer for unstructured data.
For example, a traditional OCR+template approach might need a new template for every new vendor’s invoice layout, whereas an IDP model can leverage a learned representation of “invoices” to extract the right fields even from unseen layouts.
Crucially, IDP systems are designed to improve over time. They often incorporate feedback loops: if the model got something wrong and a human corrects it, that data can be used to retrain or adjust the model (a process known as continuous learning).
As Gartner notes, the shift to ML-based document processing means continuous learning from processed documents, rather than case-by-case revision of templates and rules.
In other words, the more documents an IDP processes, the smarter it gets, exactly the kind of future-proof adaptability enterprises need.
And what about accuracy? IDP’s use of context and AI drastically reduces the error rates seen in naive OCR. Document AI services by major cloud providers (like Google Document AI, Amazon Textract, Azure Form Recognizer) boast high accuracy on complex documents by leveraging deep learning.
They can, for instance, parse a densely formatted bank statement and correctly identify the account number, balances, transactions, etc., where a vanilla OCR would just give a blob of text. One key reason is IDP doesn’t treat all text as equal, it knows what to look for.
Through NLP, it can discern that “Total Amount Due:” likely precedes a monetary value, or that a social security number has a certain pattern, etc. This semantic understanding means far fewer false positives. A study by Infosource even defined IDP as software that “acquires, classifies, and converts unstructured and semi-structured information into usable data”, highlighting handling of unstructured content as a core capability.
The result is not just faster processing, but processing that can be trusted with critical business decisions (e.g., approving a loan based on extracted income documents) without a human having to triple-check everything.
Agentic AI systems take automation a step further, from processing documents or single tasks to orchestrating entire workflows with autonomous AI agents.
The term “agentic AI” refers to AI that isn’t just assistive (like a chatbot that helps a human) but autonomous to a degree: able to take actions, make routine decisions, and dynamically handle multi-step processes.
In the context of enterprise automation, the idea is to have a team of AI agents collaborating (and also working with humans) to execute a business process from start to finish.
For example, imagine the onboarding of a new client at a bank. An agentic AI system could automatically receive the client’s emailed documents, use IDP to extract relevant data, run background checks via API, fill out internal forms, and even converse with the client for any clarifications, all as a cohesive orchestrated workflow.
This goes well beyond what RPA can do (which might at best automate some form entries). Agentic AI brings adaptability and “judgment” into the loop. As IBM explains, AI agents are powered by large language models (LLMs) and are “empowered to work autonomously with minimal human supervision, operating through various levels of complexity.” They can “reason and adapt to complete multi-step processes and sophisticated goals.”
In essence, these agents have a degree of cognitive flexibility: they might decide “if the data looks like this, take Path A; if not, try Path B or ask a human.” This is the kind of decision-making that previously only humans or very complex coded logic could do, now being handled by AI reasoning.
Notably, agentic AI systems often utilize a conversational interface or natural language logic to drive automation.
The example of IBM’s Watsonx Orchestrate is instructive: it introduced an “orchestrator agent” that can mediate a multi-turn conversation and route tasks to the correct tool, assistant, or human as needed. From a user’s perspective, one might simply chat with an AI that manages a complex request behind the scenes.
Under the hood, that orchestrator agent figures out which sub-agents or APIs need to be invoked, in what sequence, and it adapts if something unexpected occurs. This is a powerful concept, it means workflows can be executed in a dynamic, context-aware way. Rather than a rigid sequence of steps, the AI agents can adjust on the fly, much like a human case manager would.
The transformative impact is already being noted in industry. Early adopters of agentic AI and IDP are seeing faster processing times and higher automation rates in areas once deemed too complex.
For instance, in lending operations, there’s anecdotal evidence that combining IDP with generative AI co-pilots accelerates funding decisions, Hyundai Capital America reportedly reached 40% “e-funding” (automated loan funding) using Generative AI in their process.
This kind of result comes from moving beyond static OCR extractions to AI-driven decisioning. Another example is in insurance claims or customer support, where AI agents can automatically gather information, fill forms, and even draft responses, handing off to humans only the truly tricky cases.
These systems are also proving better at compliance: they can log every decision and even explain it (if using explainable AI models), addressing regulatory concerns that a tangle of RPA scripts could never fully satisfy.
Adaptability, precision, and end-to-end integration are the hallmarks of these new AI-powered automation solutions:
- Adaptability: Because they learn from data, IDP systems can handle unseen document types or changes far more gracefully than template-bound OCR. Agentic AI, with LLMs, can even handle nuances in language or unexpected user inputs during a process. They excel at the messy middle where legacy bots would throw up their hands.
- Precision: With higher semantic understanding, false positives and errors are greatly reduced. The AI doesn’t just grab any text that looks like an amount; it knows what data makes sense in context. Some IDP solutions even cross-validate extracted data (for example, ensuring an extracted total matches the sum of line items) to catch mistakes automatically. The end result is higher confidence in automation, businesses can let the AI execute tasks without as much human double-checking, because the quality is inherently better.
- End-to-End Integration: Perhaps most importantly, these intelligent systems integrate directly into business workflows rather than operating as isolated tools. Modern IDP platforms expose APIs and event triggers so that as soon as data is extracted, it flows into your downstream systems (CRM, ERP, loan origination system, etc.) without manual steps. Agentic AI by definition spans multiple tools, serving as the “glue” that connects different software via AI decision-making. For example, an AI agent might automatically move data from an email to a ticket system, then notify a Slack channel, all in one seamless chain. This kind of integration was theoretically possible with RPA, but in practice RPA bots often functioned like brittle patch cords between systems. By contrast, agentic AI approaches integration with a higher-level logic, making the workflows more resilient to change.
The momentum behind these technologies is evident. Analyst firms are now tracking Intelligent Document Processing as a distinct market, with Gartner and IDC identifying leading vendors pushing the envelope.
Likewise, forward-thinking enterprises are piloting agentic AI frameworks internally or with vendors, knowing that being able to orchestrate AI agents at scale could be a huge competitive differentiator. In the next section, we’ll look at some of the key players and solutions in this space, to understand how the industry is shifting toward this AI-driven future.

Competitive Landscape: Leading IDP and Agentic AI Solutions
The rise of IDP and agentic AI has sparked fierce competition among tech providers. Traditional OCR/RPA vendors are evolving their offerings, and new AI-native players are entering the fray. For enterprise decision-makers evaluating options, it’s useful to know who the leaders are and how they differ. Below is a snapshot of the competitive landscape:
Leading IDP Platforms (Intelligent Document Processing):
- Lightico: A next-generation IDP platform built around a patent-pending LLM model creation and orchestration framework, Lightico enables real-time document classification, data extraction, and validation within customer-facing workflows. Unlike traditional OCR or RPA-based IDP, Lightico’s system dynamically selects or creates specialized AI models per document type — ensuring higher accuracy, faster time-to-value, and zero brittle templates. Integrated natively into Lightico’s Digital Completion Cloud, it empowers enterprises to fully automate collection, I-9/E-Verify, loan documents, and ID verification — all during live mobile sessions, with no app or portal needed.
- ABBYY: A long-time pioneer in OCR, ABBYY has evolved into an IDP leader with its FlexiCapture and Vantage platforms. ABBYY leverages decades of OCR experience combined with machine learning to handle semi-structured and unstructured documents.
- UiPath Document Understanding: UiPath, known for RPA, made a strategic expansion into IDP by integrating AI-based document processing into its platform. This allows UiPath bots to intelligently handle documents as part of end-to-end processes.
- Tech Giants (Google, Microsoft, Amazon): The big cloud providers have each developed robust IDP services:
- Google Cloud Document AI offers specialized parsers for many document types (from W2 tax forms to mortgage documents), built on Google’s deep learning research. It excels in classification and structured data extraction, benefiting from Google’s enormous training data. Google was named a Leader by Forrester, reflecting its strong current offering and strategy.
- Microsoft’s Azure Form Recognizer and AI Builder provide flexible APIs to analyze forms, receipts, business cards, and more. Microsoft is considered a Strong Performer, with tight integration into the Power Platform for easy workflow incorporation.
- Amazon Textract similarly can extract printed text and structured data (tables, key-value pairs) from documents, and is often paired with Amazon Comprehend for NLP on unstructured text. AWS was noted as a Strong Performer by Forrester.
- These cloud IDP services are attractive for their scalability and pay-as-you-go model, though they might require more integration effort depending on use case. They are rapidly improving with each generation of underlying AI models (for instance, incorporating transformers like LayoutLM for better layout understanding).
Lightico’s LLM-Powered Framework: Overcoming OCR/RPA Limitations
Lightico’s LLM model creation and selection framework is a real-world example of how a platform can overcome OCR/RPA limitations through an AI-centric design.
Lightico, known for its Digital Completion Cloud, has developed an Intelligent Document Processing solution that leverages proprietary LLMs in a novel way to achieve high adaptability and accuracy. This framework is at the core of Lightico’s approach to document automation and is engineered to address precisely the pain points we discussed with legacy tools.
What is Lightico’s LLM model creation & selection framework?
In essence, it is a system where multiple AI models (including LLMs and other specialized models) are orchestrated to handle document tasks, with the ability to create new specialized models on the fly and automatically choose the best model for each job.
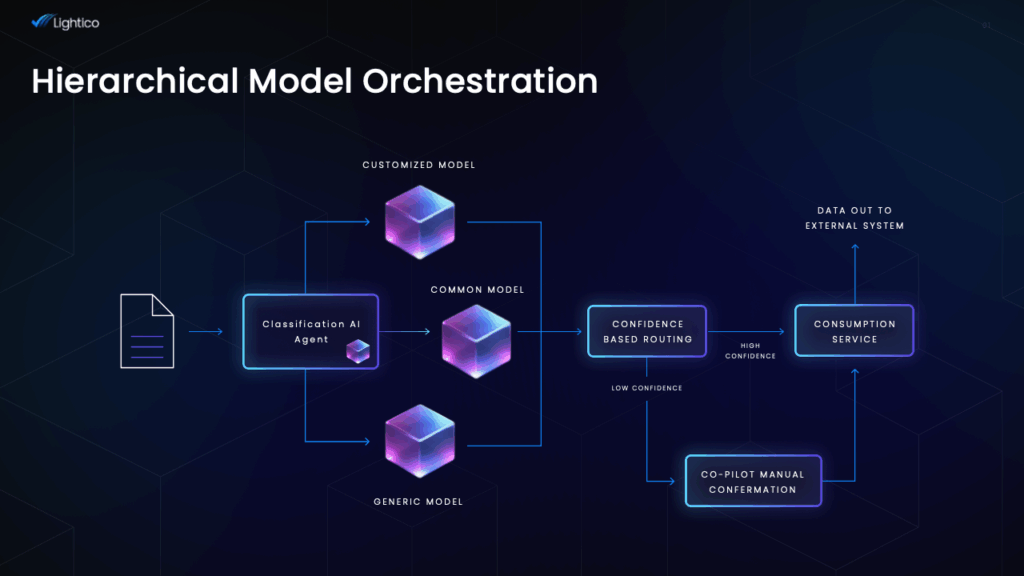
This sounds complex, but Lightico has made it seamless for the user. When a document comes in through Lightico’s platform, here’s what happens behind the scenes:
Multi-Model Orchestration
Instead of relying on a single OCR engine or one monolithic AI, Lightico’s framework has a portfolio of AI models, each with different strengths (some are better at handwriting, some excel at tabular data, some are fine-tuned for legal language, etc.). Gartner explicitly recommends this model-portfolio approach, urging buyers to “focus on [a vendor’s] ability to marshal a portfolio of models…to meet the needs of specific document types and processes.”.
Lightico’s system embodies that advice. It can dynamically select the optimal model or combination of models based on the document type and content. For example, if a customer uploads a pay stub vs. a driver’s license vs. a bank statement, the framework might route each to different AI models specialized for those formats. This automatic model selection is crucial for maximizing accuracy, it’s like having a team of expert readers and always picking the one best suited to the task.
On-Demand Model Creation (Customization)
Patent-pending is the process by which Lightico can create new LLM instances or fine-tuned models rapidly when a new document type or use-case emerges. Think of it as a factory for custom AI models. If Lightico encounters, say, a very domain-specific form that the existing models don’t handle with high confidence, the framework can spawn a new model trained (or prompted) on examples of that form. This might involve transfer learning on an LLM, leveraging a base large language model and fine-tuning it with a small set of documents from that domain.
The key is this can be done faster and with less data than traditional model training, thanks to advanced techniques and Lightico’s IP.
Strategically, this means Lightico’s solution never hits a wall: new requirements don’t require waiting for a vendor’s next release or writing brittle regex rules; the platform itself can evolve by generating a model tailored to the need. This adaptiveness addresses the legacy “one-size-fits-all” issue, instead of forcing every problem through one OCR engine, Lightico spins up a bespoke AI if needed.
Integrated Workflow Actions
Lightico’s IDP doesn’t operate in isolation, it’s deeply integrated into the Digital Completion workflow. When a document is submitted by a customer (for example, via a mobile link in an SMS), the system goes to work: “The document is processed, categorized, classified, and has the data extracted and analyzed by AI.” All of that happens in one continuous flow, within seconds, during the live customer session.
This is an important point both technically and strategically. Technically, it means the output of the AI (the extracted data, the classification result) is immediately available to drive next steps, e.g., auto-filling a form, triggering a decision, or asking the customer for a missing document. No human middleware is required to move data around; no separate RPA bot is needed to take OCR text and paste it somewhere.
Strategically, this end-to-end integration means faster turnaround times and a smoother customer experience. There’s no “we’ll get back to you in 24 hours after we process your documents”, it’s often instantaneous. In industries like auto lending or insurance, this speed can be a competitive differentiator (customers get approvals or quotes in minutes, not days).
In practice, Lightico’s LLM-powered framework has shown impressive results. By embedding it in the customer-facing journey, they’ve seen metrics like improved completion rates and faster funding times. For instance, with automation handling document intake and validation, some lenders have achieved 16% faster time-to-funding for loans and nearly all customers (94%) completing e-signatures successfully on the first pass.
These outcomes speak to a reduction in friction, when documents are processed correctly and immediately, downstream steps (signing, approvals) happen smoothly without back-and-forth. It’s the elimination of errors and delays that creates a compounding benefit to the business: more efficiency, better customer satisfaction, and ultimately higher conversion rates (more deals closed, loans booked, policies issued, etc.).
From a technical strategy perspective, Lightico’s approach aligns with a future where AI is woven into every step of the business process.
Instead of patching legacy tools into modern workflows, Lightico rebuilt the document workflow around AI from the ground up. This gives them an edge in adaptability, as new AI advancements come (say newer, more powerful LLMs), their framework can incorporate those by adding them to the model portfolio or swapping out a component. It’s a modular, ModelOps-driven design. For customers, that means investing in Lightico is investing in a platform that will keep pace with AI innovation, rather than a static tool that might be outdated in a year.
The patent-pending nature of the LLM model framework is uniquely difficult, likely in how they balance multiple models and achieve quick model creation. That intellectual property can become a moat, ensuring that Lightico continues to deliver best-in-class accuracy and flexibility.
In summary, Lightico’s LLM-based IDP framework exemplifies how to overcome OCR/RPA limitations: it’s adaptive (via model selection/creation), precise (via LLM understanding + validation), and end-to-end integrated (via workflow embedding). It tackles the false positives by understanding context, tackles brittleness by using learning models instead of fixed rules, and tackles complexity by hiding it behind an easy interface. Strategically, it means companies using Lightico can automate customer-facing document workflows in a way that is truly scalable and future-proof.
They aren’t just replacing paper with PDFs (digitization); they are transforming the entire process with intelligence.
Embracing the AI-Powered Automation Future
Traditional OCR and RPA had their moment, but the demands of modern enterprises have outgrown what “templated” automation can offer. High error rates, brittle processes, and labor-intensive upkeep make them increasingly unsustainable in a world where 80-90% of data is unstructured and business needs shift rapidly. The next generation of automation, powered by IDP and agentic AI, is already proving its worth by dramatically improving accuracy, adaptability, and speed in enterprise workflows. These AI-driven systems don’t just do the old things faster; they enable entirely new levels of efficiency and customer experience by handling tasks that used to require human intuition.
For IT leaders and developers, the message is clear: automation must evolve from rigid scripts to intelligent, learning systems. Intelligent Document Processing solutions can read and understand documents at scale, and AI agents can take on complex workflows, not as brittle bots, but as adaptive digital colleagues. The competitive comparisons show that vendors who embrace AI (adding model-driven capabilities and end-to-end integration) are leading the pack, while those sticking to purely rules-based automation are lagging.
Lightico’s approach using the LLM model creation and selection framework, offers a blueprint for how to navigate this new era.
By leveraging a portfolio of AI models and dynamically orchestrating them, Lightico ensures that automation is resilient to change and tailored to context, exactly what enterprises need to future-proof their operations.
The success Lightico’s clients are seeing (faster processes, higher completion rates, happier customers) underscores a broader point: when you eliminate the friction and errors caused by legacy OCR/RPA, you unlock massive gains in productivity and customer satisfaction.
The AI-powered future of automation is here.
